Scaling up SFU is primarily about increasing the number of users that can connect in total and the number of users that can connect to each meeting. The main method of achieving this is to reduce the number of packets SFU actually needs to receive, decrypt and forward. Another aspect is to allow a client to participate in a meeting with 1000 participants without breaking down the call setup, or cause millions of call setup updates as a thousand people join the meeting.
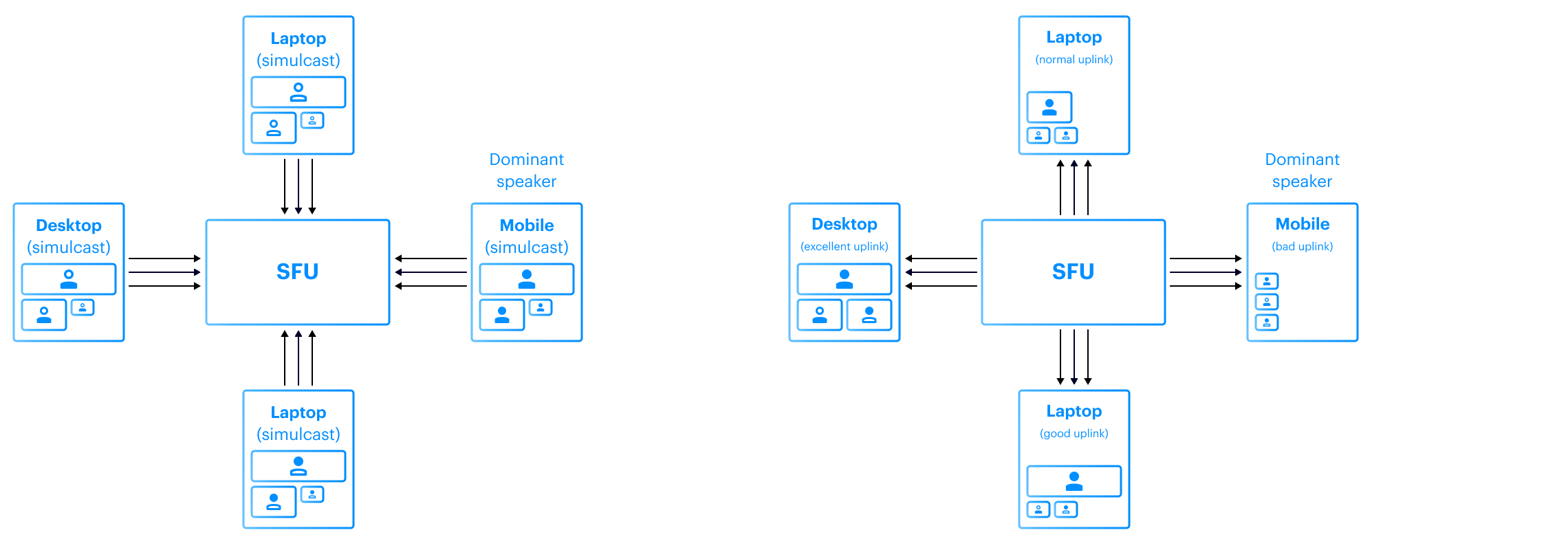
The SFU also has to be smart with regards to bandwidth. If there is insufficient bandwidth, forwarding more streams to a client will not be successful. The SFU may adjust and pick lower bit rate streams to forward if the client cannot display the streams in high resolution.
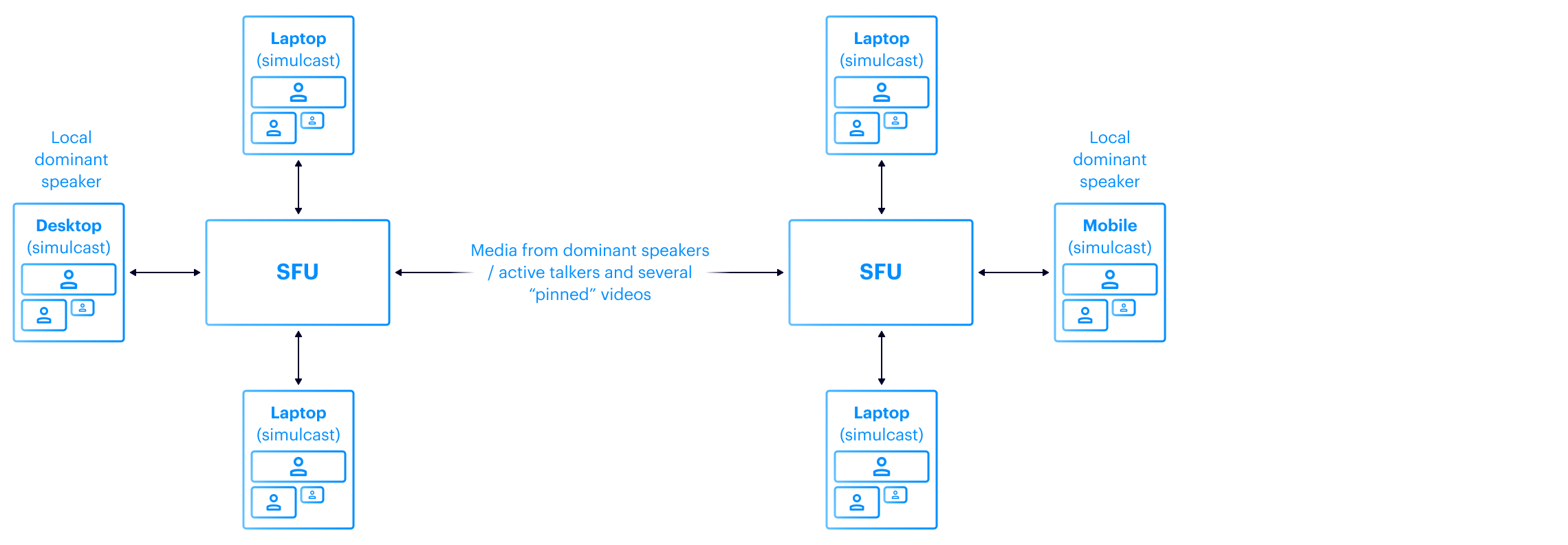
Once the capacity of a single SFU has been exhausted, the only way to continue scaling out is to involve multiple SFUs in the same meeting, by connecting them in a mesh, aka barbelling. While a single SFU forwards a set of streams to each participant, it only has to forward that set once to another SFU to allow that second SFU to forward it again to all its participants.
There are three particular problems that one faces trying to increase the number of participants of the video conference:
- SSRC mapping;
- Bandwidth constraints;
- Multi-location (multi-SFU) conferencing.
Let’s describe them first one by one before showing how we managed to solve them altogether.
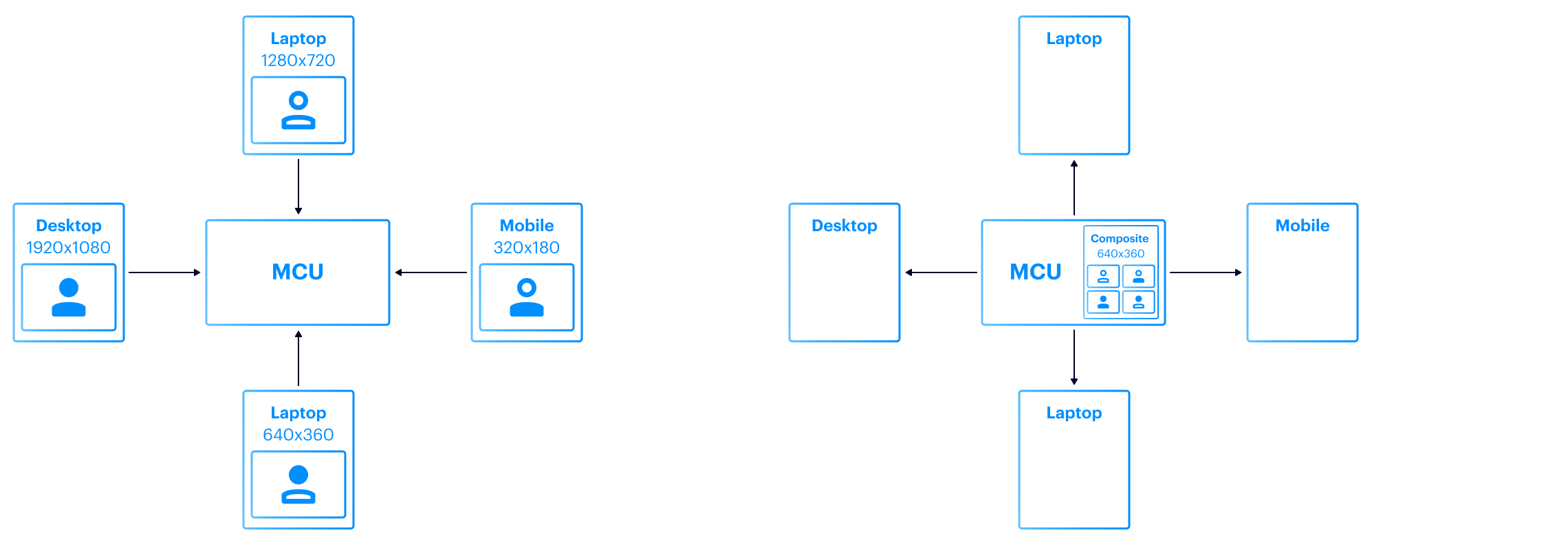
To provide a context, we’ll start with an overview of what each endpoint receives. SFU sends each endpoint a collection of audio and video RTP streams. Each media stream is labeled with an identifier which is known as synchronization source (SSRC). SSRC in a nutshell is a simple digital label, present in various RTP headers, that allows the receiver to understand “who’s this data is from” from the multiplex of RTP streams it receives. Clients use SSRC whenever it needs to identify the media source, e.g. when requesting SFU to resend some packets if a packet loss is detected, or for UI purposes.
Thus, adding a new participant to an existing conference requires extensive interchange of signaling information in the form of SDP (Session Description Protocol) data between the server and each endpoint. SDP, among other things, bears mapping of media channels to the SSRCs. As the number of participants grows, SDP lineary grows as well, and needs to be sent to each endpoint, which makes the SDP traffic grow quadratically. SMB solves this problem by re-using limited numbers of SSRC and supplementing SDP with SSRC mapping messages in a custom protocol. We call this technique SSRC-rewriting.
The second problem arises from the fact that the endpoint’s resources like bandwidth and CPU are limited. It can’t receive and decode video from all other participants. Moreover, it makes little sense to do so, since “real estate” in UI is limited as well: it has no practical use to display thousands of thumbnail-sized videos when in fact there are a few (usually one) people talking and presenting (e.g. slides). SMB’s take on that is that at most we forward some limited ‘N’ (e.g., 9) number of videos to each participant, depending on who’s presenting, the client’s bandwidth, who’s active speaker and other factors.
The last problem we face happens because the server’s resources are limited as well: with all the optimization implemented, there is still a clear limit on how many participants an SFU server with a limited CPU and Memory can serve. SMB provides an API to build a mesh of SMB servers to solve this. In the simplest configuration, it is two SMB servers working together, with the topology that looks like a “barbell” – where the “bar” is the connection between two SMBs. Thus we call this API barbelling.