
Tech4Fin
The Future of Mission-Critical Voice: Looking Ahead At The Next 10 Years
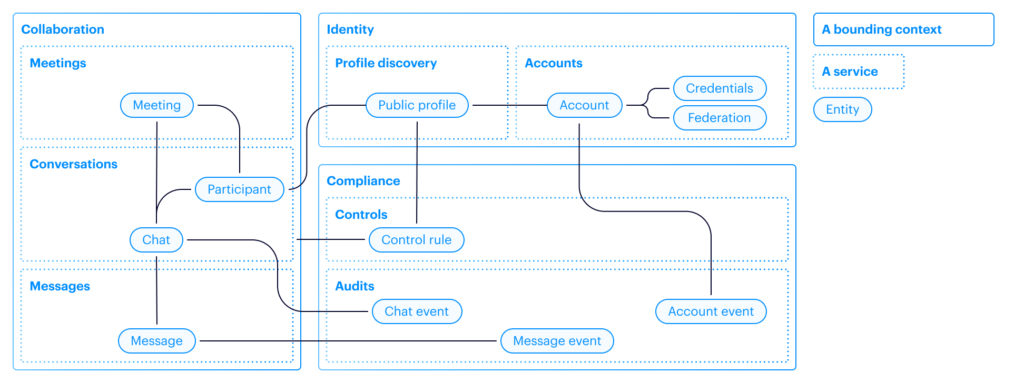
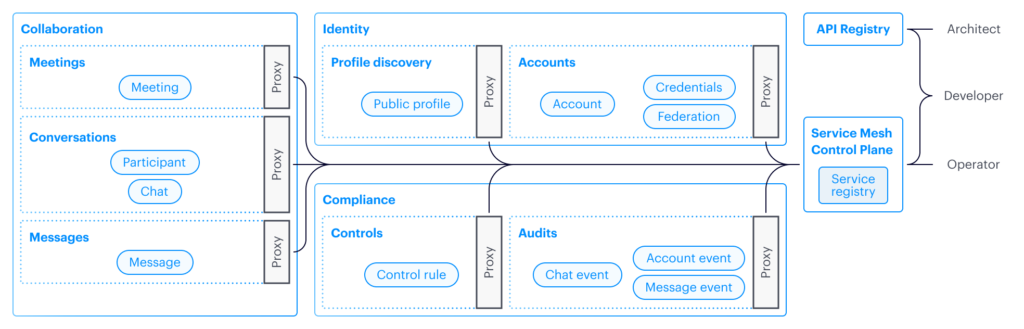
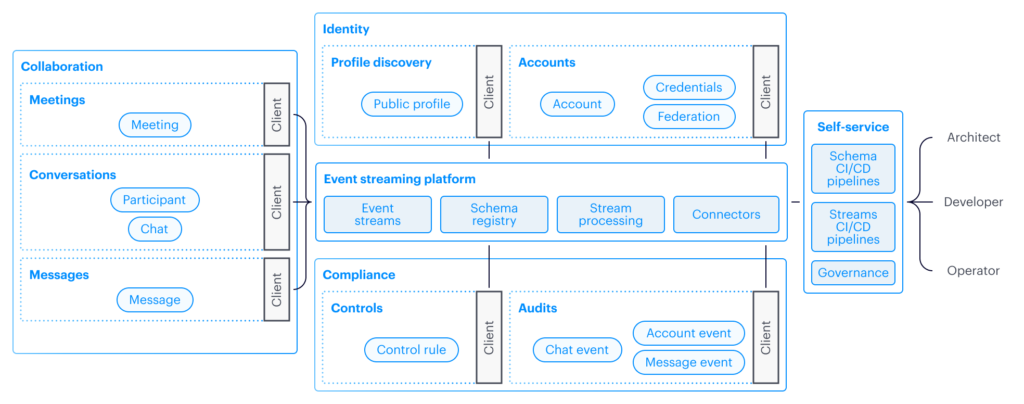
The next decade of voice communication will look radically different than the past 10 years. Today’s (and certainly tomorrow’s) trader demands technology that is fundamentally incompatible with the rigidity of legacy systems – workers are increasingly reliant on mobile, flexible workplaces and AI. The end of the on-premise era brings an imperative for critical trading systems to deliver not only zero-downtime reliability but also unprecedented flexibility across multiple endpoints with integrated intelligence.

